


数据库领域图灵奖获得者 Jim Gray 说过:“所有的存储系统最终都会演变成数据库系统。”数据库系统经过几十年演进后,分布式数据库在近几年发展如火如荼,国内外出现了很多分布式数据库创业公司,为什么分布式数据库开始流行?在计算机历史上出现过数百个数据库系统,为什么我们需要分布式数据库?为何走向分布式数据库让我们追溯数据库发展历史,看看分布式数据库为何出现。
当然,这类方案也有一些缺点,例如:
- 不支持跨分片事务;
- 重新分片是困难的,会成为数据库管理员的噩梦;
这些事情都是为了追求可扩展性。为此,这些公司还开发了 NoSQL,不惜放弃了关系模型,放弃了事务,放弃了数据一致性保证(有的 NoSQL 只保证最终一致性)。前文提到,20世纪70年代 Edgar Frank Codd 为了减轻开发人员心智负担而设计了关系型数据库,而 NoSQL 解决了应用程序所需的可扩展性,但又好似退回到了以前,程序员又要面临 NoSQL 功能不足的问题——也就是 Jim Gray 所说的:“所有的存储系统最终都会演变成数据库系统。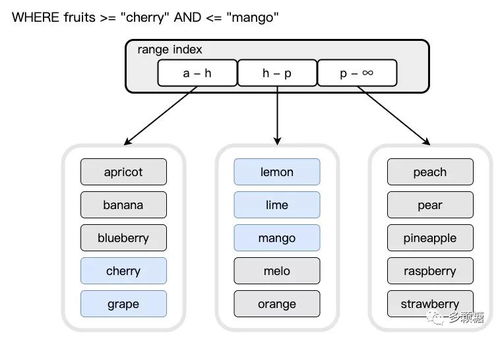
”2010 年代:分布式数据库为什么要构建分布式数据库呢?通过历史发展分析应该相当清楚了,现有的数据库解决方案给开发者和管理员带来了过重的负担。
当你开始一个新的大项目,选择一个单点数据库会牺牲掉未来的可扩展性,选择一个 NoSQL 又会让开发者承受额外的负担来解决问题,并且可能不支持事务等优秀的功能。分布式数据库试图结合两者优点,构建成为两全其美的系统:既能支持完整的关系模型,又能提供高可扩展性和可用性。分布式数据库常被称为 NewSQL 或 Distributed SQL——无论怎么称呼,都指那些在多台机器运行的数据库。
这不是说 NoSQL 是完全没用的,事实上人们在 NoSQL 上构建了许多成功的系统,但这要困难得多。Google 的分布式数据库 Spanner 论文中有一句话:
We believe it is better to have application programmers deal with performance problems due to overuse of transactions as bottlenecks arise, rather than always coding around the lack of transactions.翻译过来就是:“我们认为最好让应用程序开发者来解决因过度使用事务而导致的性能问题,而不是让开发者总是围绕着缺少事务编写代码。
”也就是说,事务是否会造成性能影响的应该由业务开发者来考虑,而作为一个数据库必须提供事务机制,来满足各种应用常见的需求。
Spanner 论文发表后,开始涌现出许多优秀的开源分布式数据库,其中具有代表性的有:CockroachDB、TiDB、YugabyteDB 和最近开源的 Oceanbase 等等。通过回顾数据库历史进程,我们知道了为什么出现分布式数据库,现在我们要关注如何实现分布式数据库。如何实现分布式数据库分布式数据库我们关注:
- 数据如何在机器上分布;
- 数据副本如何保持一致性;
- 如何支持 SQL;
- 分布式事务如何实现;
当然,本文只会简述分布式数据库的简单原理,许多细节不会涉及,如果你想要深入学习,除了学习源代码外,可以关注笔者的公众号和笔者下半年将要出版的书籍。数据分布NewSQL 和 NoSQL 的数据分布是类似的,他们都认为所有数据不适合存放在一台机器上,必须分片存储。因此需要考虑:
- 如何划分分片?
- 如何定位特定的数据?
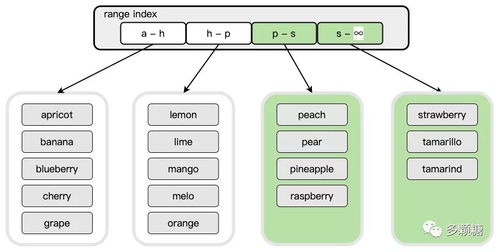
范围分片指按照某个范围划分数据存储的位置,举个最简单的例子,按照首字母从 A-Z 分为 26 个分区,这样的分片方式对于范围查询非常有用;缺点是通常需要对关键字进行查询才知道数据处于哪个节点,这看起来会造成一些性能损耗,但由于范围很少会改变,很容易将范围信息缓存起来。例如下图所示,我们按照关键字划分为三个范围:[a 开头,h 开头)、[h 开头,p 开头)、[p 开头,无穷)。我们关心的最后一个问题是,当某个分片的数据过大,超过我们所设的阈值时,如何扩展分片?由于有一个中间层进行转换,这也很容易进行,只需要在现有的范围中选取某个点,然后将该范围一分为二,便得到两个分区。如下图所示,当 p-z 的数据量超过阈值,为了避免负载压力,我们拆分该范围。
软件工程没有银弹,使用共识算法仍然需要面临许多生产问题,例如成员变更、范围分区变更、实现线性一致性等等问题都要去克服。只不过现在我们有了坚实的学术支撑,这样进行复制是正确的。SQL 表数据 KV 化存储解决了 KV 存储以后,我们还要想办法用 KV 结构来存储表结构。通常,增删查改可以抽象成如下 5 个 KV 操作(也许可以再多些,但基本就是这些)。
这样看不大直观,举个例子,对于以下建表语句: 最后,在数据库领域获得图灵奖的学者不多,一共 Charles Bachman、Edgar Frank Codd、Jim Gray、Michael Stonebraker 四位大师,本文提到了其中前三位。2020 年图灵奖获得者 Jeffrey Ullman 虽然在数据库领域也有所建树,但他是因为编程语言领域(“龙书”)而获奖,而非在数据库领域获奖。
陈金凌:5大工具搭建独立站项目!(你用过几个) 数字化转型是什么?怎么做?(落地篇) 高并发,我把握不住啊! 3500字归纳总结!一名合格的软件测试工程师需要掌握的技能大全 转行数据分析,找不到工作怎么办? 如何搭建一个卖云主机的网站? 2022 程序员重要数字资产:WordPress 快速搭建个人独立网站 phpstudy搭建网站教程(phpstudy怎么安装源码) 搭建个人博客网站——2、更改数据库为mysql并连接数据库 asp.net课程网站系统VS开发sqlserver数据库web结构c#编程计算机网页源码项目 BPC Hyperion TM1 华为云PB级数据库GaussDB(for Redis)揭秘第八期:用高斯 Redis 进行计数 Google论文、开源与云计算 作为产品经理你应该了解一些技术知识 一些著名的软件都用什么语言编写?GetPutConditionalPutScanDel我们讨论的是 OLTP 类分布式数据库都是行存。我们以 CockroachDB 举例,一个表通常包含行和列,可以将一个表转换成如下结构://
/ 这部分表示需要每个表必须有一个主键。CREATE TABLE test ;转换成 KV 存储如图所示:非唯一索引和主键类似,只不过其值为空。如图所示:开源造福人类,如今涌现了许多优秀的开源分布式数据库,他们都是很好的学习材料,笔者也会在后续文章中继续分享 CockroachDB、TiDB、YugabyteDB 和 Oceanbase 的技术细节。感谢这些开源者。
如遇本文系为网络转载到本站发表,图片或文章有版权问题的请联系客服确认后会立即删除文章。
如遇本文系作者授权本站发表,未经许可,不得转载。















